
Existen una serie de problemas en las instituciones sobre como poder recolectar los datos de varios lugares o formaticos.
Por lo tanto, cuando se mueven de un lugar a otro, es posible que el destino no sea el mismo que el del origen, por lo tato con los años se han intentado desarrollar servicios o aplicaciones para poder solucionar esos problemas, pero gracias a ETL se puede lograr cierto control de la base de datos.

ETL en los años 1970, cuando hubo la necesidad de integrar datos, ETL se convirtió en un método para poder extraer los datos y llevarlos a su destino.
Luego en el 1990, apareció el famoso «data waewhouse», que es un tipo de base que tienen un acceso a múltiples sistemas, a minicumputadoras, a computadoras personales y a hojas de cálculos. Pero varias organizaciones usaban las herramientas ETL para almacener didtintos datos. A medida que paso el tiempo. los sistemas de datos aumentaron a escalas mayores.
¿Qué es un ETL?
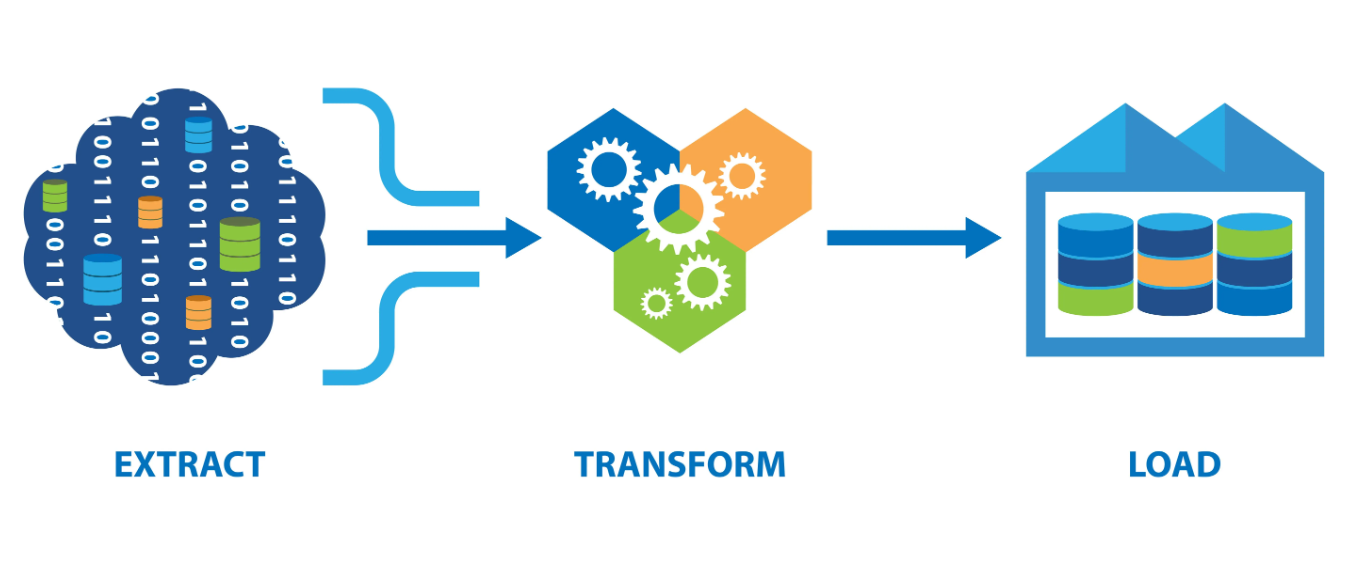
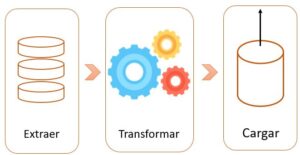
Es una agregación de datos que incluye el extraer, transformar y cargar una serie de datos de varias fuentes.
Es importante para poder almacenar los datos.
Primero los datos se extraen de sus sistema de origen, luego se convierten en un formato en donde se puede almacenar y luego se van a un sistema diferente o una data warehouse.
¿Porqué es importante el ETL?
Es importante por varias razones, entre ellas son:
- Se puede usar en los datos empresariales, puede darnos contenido historico de todos los datos de la empresa.
- Permite mejorar la productividadad de los datos.
- Reutiliza los procesos sin necesidad tener conocimientos sobre programación
- Permite poder analizar sobre los reportes de los datos.
- Permite una mayor precision en las empresas.
- Proporciona una serie de recursos que se necesitan en los almacenes y en el análisis de datos.
¿Cómo se debe de llevar a cabo cada una de las fases anteriormente mencionadas?
Primera fase (La Extracción)
Segunda fase (Transformación)
Tercera fase (Carga)
Fase de Extracción en los procesos ETL
Para llevar a cabo de manera correcta el proceso de extracción, primera fase de los procesos ETL, hay que
seguir los siguientes pasos:
● Extraer los datos desde los sistemas de origen.
● Analizar los datos extraídos obteniendo un chequeo.
● Interpretar este chequeo para verificar que los datos extraídos cumplen la pauta o
estructura que se esperaba. Si no fuese así, los datos deberían ser rechazados.
● Convertir los datos a un formato preparado para iniciar el proceso de transformación
Además, uno de las prevenciones más importantes que se deben tener en cuenta durante el proceso de extracción sería el exigir siempre que esta tarea cause un impacto mínimo en el sistema de origen. Este requisito se basa en la práctica ya que, si los datos a extraer son muchos, el sistema de origen se podría ralentizar e incluso colapsar, provocando que no pudiera volver a ser utilizado con normalidad para su uso cotidiano.
Procesos ETL: fase de Transformación
La fase de transformación de los procesos de ETL aplica una serie de reglas de negocio o funciones sobre los datos extraídos para convertirlos en datos que serán cargados. Estas directrices pueden ser declarativas, pueden basarse en excepciones o restricciones pero, para potenciar su pragmatismo y eficacia, hay que asegurarse de que sean:
● Declarativas.
● Independientes.
● Claras.
● Inteligibles.
● Con una finalidad útil para el negocio.
Proceso de Carga: la culminación de los procesos ETL
En esta fase, los datos procedentes de la fase anterior (fase de transformación) son cargados en el sistema de destino. Dependiendo de los requerimientos de la organización, este proceso puede abarcar una amplia variedad de acciones diferentes.
Existen dos formas básicas de desarrollar el proceso de carga:
● Acumulación simple: esta manera de cargar los datos consiste en realizar un resumen de todas las transacciones comprendidas en el período de tiempo seleccionado y transportar el resultado como una única transacción hacia el data warehouse, almacenando un valor calculado que consistirá típicamente en un sumatorio o un promedio de la magnitud considerada. Es la forma más sencilla y común de llevar a cabo el proceso de carga.
● Rolling: este proceso sería el más recomendable en los casos en que se busque mantener varios niveles de granularidad. Para ello se almacena información resumida a distintos niveles, correspondientes a distintas agrupaciones de la unidad de tiempo o diferentes niveles jerárquicos en alguna o varias de las dimensiones de la magnitud almacenada (por ejemplo, totales diarios, totales semanales, totales mensuales, etc.).
Sea cual sea la manera elegida de desarrollar este proceso, hay que tener en cuenta que esta fase interactúa directamente con la base de datos de destino y, por eso, al realizar esta operación se aplicarán todas las restricciones que se hayan definido en ésta. Si están bien definidas, la calidad de los datos en el proceso ETL estará garantizada.