

BIG DATA
Big data es un término utilizado para describir un gran volumen de datos, tanto estructurados como no estructurados, que es difícil de procesar mediante técnicas de almacenamiento y procesamiento de datos convencionales.
Esto incluye datos generados por sensores, dispositivos móviles, transacciones en línea, y otras fuentes digitales.
El análisis de big data se utiliza para descubrir patrones, tendencias y conocimientos útiles que ayudan a mejorar las decisiones de negocio, la investigación científica y el desarrollo de nuevos productos.
¿PARA QUE SIRVE EL BIG DATA?

El Big data se utiliza para una variedad de propósitos, incluyendo:
Toma de decisiones: Los datos recopilados de diferentes fuentes pueden ayudar a las empresas a tomar decisiones informadas y mejorar su eficiencia.
Análisis predictivo: El análisis de datos históricos puede ayudar a predecir el comportamiento futuro y a tomar medidas preventivas.
Personalización: El análisis de datos sobre los clientes puede ayudar a las empresas a ofrecer productos y servicios personalizados.
Investigación: Los datos recopilados de diferentes fuentes pueden utilizarse en investigaciones científicas para descubrir patrones y tendencias.
Optimización de procesos: El análisis de datos puede ayudar a las empresas a optimizar sus procesos internos y a reducir costos.
Mejora de la seguridad: El análisis de datos puede ayudar a detectar anomalías y amenazas potenciales a la seguridad de la información.
¿COMO FUNCIONA EL BIG DATA?
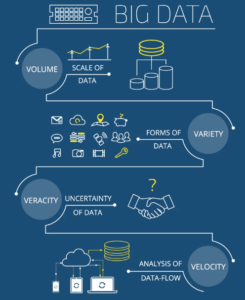
El procesamiento de Big data se lleva a cabo mediante una combinación de herramientas y tecnologías.
El proceso generalmente se divide en tres fases:
Recolección de datos: Los datos se recopilan de una variedad de fuentes, como sensores, dispositivos móviles, transacciones en línea, y otras fuentes digitales.
Estos datos pueden ser estructurados o no estructurados y pueden incluir texto, imágenes, audio y video.
Almacenamiento de datos: Una vez recolectados, los datos se almacenan en sistemas de almacenamiento distribuidos, como Hadoop o NoSQL.
Estos sistemas son escalables y se pueden adaptar a grandes cantidades de datos.
Análisis de datos: Los datos se analizan utilizando herramientas de análisis de datos, como Spark, Storm, y R, para descubrir patrones y tendencias.
Los datos también pueden ser procesados en tiempo real mediante el uso de tecnologías como Streaming.
Los resultados del análisis se pueden utilizar para mejorar las decisiones de negocio, la investigación científica y el desarrollo de nuevos productos.
Además de estas fases, también existen herramientas de inteligencia artificial y aprendizaje automático que se utilizan para mejorar el análisis de datos y la capacidad predictiva.
INGENIERO DE BIG DATA

Un ingeniero de Big data es un profesional especializado en el manejo y el procesamiento de grandes volúmenes de datos, tanto estructurados como no estructurados.
¿QUE HACE EL INGENIERO DE BIG DATA?

Diseño e implementación de arquitecturas de almacenamiento y procesamiento de datos distribuidas, como Hadoop o NoSQL.
Recolección y limpieza de datos de diferentes fuentes, como sensores, dispositivos móviles, transacciones en línea, y otras fuentes digitales.
Análisis de datos utilizando herramientas de análisis de datos, como Spark, Storm, y R, para descubrir patrones y tendencias.
Implementación de técnicas de inteligencia artificial y aprendizaje automático para mejorar el análisis de datos y la capacidad predictiva.
Diseño e implementación de soluciones de seguridad para proteger los datos recolectados.
Trabajar con equipos de desarrollo y otros departamentos para asegurar que los datos recolectados se utilicen de manera efectiva para mejorar las decisiones de negocio y el rendimiento de la empresa.
Un ingeniero de Big data debe tener una sólida comprensión de las tecnologías de Big data , así como habilidades para programar y tener conocimiento en matemáticas y estadística.
También es importante tener habilidades para resolver problemas y tomar decisiones informadas.
¿CUANTO GANA UN INGENIERO DE BIG DATA?
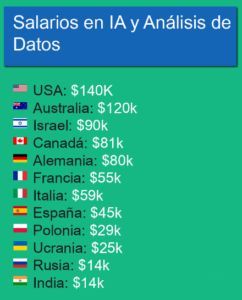
El salario de un ingeniero de Big data puede variar dependiendo de varios factores, como la ubicación, la experiencia, la industria y la empresa en la que trabajen. En promedio, un ingeniero de Big Data puede ganar entre $80,000 y $160,000 al año en los Estados Unidos.
Los ingenieros con experiencia y habilidades avanzadas pueden ganar más de $160,000 al año, mientras que los recién graduados y los con menos experiencia pueden ganar menos de $80,000 al año.
El salario de un ingeniero de Big data en Latinoamérica puede variar dependiendo de varios factores, como la ubicación, la experiencia, la industria y la empresa en la que trabajen.
los salarios para ingenieros de Big data en Latinoamérica son menores en comparación con los Estados Unidos.
El salario promedio para un ingeniero de Big data en Latinoamérica puede estar entre $40,000 y $80,000 al año.
Sin embargo, es importante mencionar que esta información puede variar dependiendo del lugar geográfico y la industria específica.
Es importante señalar que también hay una gran diferencia entre los países de Latinoamérica en cuanto a salarios y costo de vida, por lo que es importante investigar en detalle antes de tomar una decisión.
¿DONDE PUEDE TRABAJAR UN INGENIERO DE BIG DATA?

Un ingeniero de Big data puede trabajar en una variedad de industrias y empresas que manejan grandes volúmenes de datos, algunos ejemplos son:
Tecnología: Las empresas de tecnología, como Google, Amazon, Microsoft y Facebook, utilizan Big Data para mejorar sus productos y servicios, así como para ofrecer anuncios personalizados.
Finanzas: Las empresas financieras, como los bancos y las aseguradoras, utilizan Big Data para detectar fraude, identificar patrones de comportamiento de los clientes y mejorar los productos y servicios.
Retail: Las empresas de retail, como Walmart, Amazon y Target, utilizan Big data para mejorar el inventario, la logística y el marketing.
Salud: Las empresas de salud, como los hospitales y las compañías farmacéuticas, utilizan Big data para mejorar la atención médica, la investigación y el desarrollo de nuevos productos.
Fabricación: Las empresas de fabricación, como GE y Boeing, utilizan Big data para mejorar el rendimiento de los equipos, la seguridad y la eficiencia operativa.
Gobierno: Los gobiernos utilizan Big data para mejorar la eficiencia operativa, la seguridad, la toma de decisiones y la implementación de políticas públicas.
Un ingeniero de Big data también puede trabajar en empresas de consultoría o en agencias de investigación, o incluso trabajar de manera independiente como consultor o contratista.
¿CUALES SON LAS APLICACIONES DEL BIG DATA?
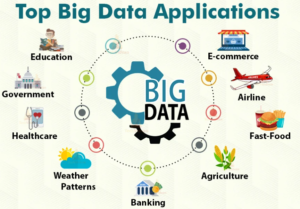
Las aplicaciones del Big Data incluyen:
Análisis de datos en tiempo real para tomar decisiones informadas
Mejora de la eficiencia operativa en empresas
Personalización de la experiencia del cliente
Identificación de patrones y tendencias en los datos
Análisis predictivo para el pronóstico de tendencias y resultados futuros
Análisis de redes sociales para el monitoreo de la opinión pública
Identificación de fraudes en transacciones financieras.
INGENIERO JUNIOR DE BIG DATA
Un ingeniero junior de Big Data es un profesional que se encarga de recolectar, almacenar, procesar y analizar grandes cantidades de datos (conocidos como «Big data «) con el objetivo de extraer información valiosa y útil para las empresas.
Entre las tareas comunes que puede realizar un ingeniero junior de Big data se encuentran:
Diseñar y desarrollar soluciones de almacenamiento y procesamiento de datos a gran escala.
Utilizar herramientas y tecnologías de Big Data para recolectar, limpiar y transformar datos.
Realizar análisis exploratorios y estadísticos en los datos para identificar patrones y tendencias.
Crear visualizaciones y reportes para comunicar los hallazgos a los diferentes departamentos de la empresa.
Proporcionar soporte y mantenimiento a las soluciones de Big Data implementadas.
Trabajar en equipo con otros profesionales como científicos de datos, analistas y desarrolladores.
Es importante destacar que los ingenieros junior de Big Data deben tener habilidades técnicas sólidas en programación, matemáticas y estadísticas, así como una buena comprensión de las tecnologías de Big Data, como Hadoop, Spark, NoSQL, entre otros.
¿PORQUE DEBES CONVERTIRTE EN UN INGENIERO DE BIG DATA?
Convertirse en un ingeniero de Big Data en el 2023 puede ser una excelente opción debido a varias razones:
Demanda en el mercado laboral: El crecimiento en el volumen de datos y la necesidad de analizarlos para tomar decisiones informadas está generando una gran demanda de profesionales en el campo del Big Data.
Salarios atractivos: Los ingenieros de Big Data son altamente valorados en el mercado laboral y se espera que sus salarios sigan creciendo en el futuro.
Oportunidades de carrera: Las habilidades y conocimientos adquiridos como ingeniero de Big Data son altamente transferibles y pueden llevar a oportunidades de carrera en áreas como la inteligencia artificial, el aprendizaje automático y la ciencia de datos.
Impacto en la sociedad: Los ingenieros de Big Data juegan un papel importante en la toma de decisiones en una variedad de campos, como la salud, la finanzas, el transporte, entre otros, y pueden contribuir al desarrollo sostenible y a mejorar la calidad de vida de las personas.
Avances Tecnológicos: El campo del Big Data está en constante evolución, con nuevas tecnologías y herramientas que surgen constantemente.
Esto significa que los ingenieros de Big Data estarán en una posición para aprender y aplicar las últimas tendencias y avances en el campo.
¿COMO PUEDO EMPEZAR EN BIG DATA?
Para empezar en el campo del Big Data, hay varios pasos que puedes seguir:
Adquirir conocimientos básicos: Aprende los conceptos básicos de Big Data, como el almacenamiento de datos distribuidos, el procesamiento en paralelo, el análisis de datos, las bases de datos NoSQL, entre otros.
Aprender un lenguaje de programación: Aprende al menos un lenguaje de programación popular como Python, Java o Scala. Son útiles para trabajar con herramientas de Big Data.
Familiarizarse con las herramientas de Big Data: Aprende a usar herramientas populares de Big Data como Hadoop, Spark y Hive. Puedes encontrar tutoriales y cursos en línea para aprender a usarlas.
Practicar con conjuntos de datos reales: Practica trabajando con conjuntos de datos reales para poner en práctica tus habilidades y conocimientos. Puedes encontrar conjuntos de datos abiertos en línea para descargar e investigar.
Participar en comunidades: Participa en comunidades en línea y eventos locales relacionados con Big Data para mantenerte actualizado y conectado con otros profesionales en el campo.
Obtener certificaciones: Obtener certificaciones en tecnologías y herramientas específicas de Big Data puede ayudar a mejorar tus habilidades y aumentar tus oportunidades de carrera.
Buscar oportunidades de trabajo: Una vez que tengas experiencia, busca oportunidades de trabajo relacionadas con Big Data. Puedes buscar en sitios web de empleo o en las páginas web de las empresas.
¿QUE ES EL DATA MARKETING?

El data marketing es el uso de datos para mejorar las estrategias de marketing y tomar decisiones informadas.
Implica recolectar, almacenar y analizar datos del cliente para comprender mejor su comportamiento de compra y las tendencias del mercado.
Con esta información, las empresas pueden personalizar su mensaje y ofrecer contenido y ofertas relevantes a su audiencia.
El data marketing también se utiliza para medir el rendimiento de las campañas de marketing, identificar patrones y tendencias en el comportamiento del cliente, y mejorar la segmentación y el targeting de las campañas publicitarias.
La herramientas utilizadas en el data marketing incluyen el análisis de datos, el aprendizaje automático, la inteligencia artificial y la visualización de datos.
Estas tecnologías ayudan a las empresas a procesar grandes cantidades de datos y a generar insights valiosos para mejorar su marketing.
¿QUE ES EL BIG DATA MARKETING?
El Big Data Marketing se refiere al uso de grandes cantidades de datos (conocido como «Big Data«) para mejorar las estrategias de marketing y tomar decisiones informadas.
A diferencia del data marketing, el Big Data Marketing se enfoca en el uso de volúmenes masivos de datos, incluyendo datos estructurados y no estructurados, para generar insights valiosos.
El Big Data Marketing implica recolectar, almacenar y analizar datos de diversas fuentes, como redes sociales, sitios web, dispositivos móviles, aplicaciones, entre otros, para comprender mejor el comportamiento del cliente y las tendencias del mercado.
Con esta información, las empresas pueden personalizar su mensaje y ofrecer contenido y ofertas relevantes a su audiencia.
El Big Data Marketing también se utiliza para medir el rendimiento de las campañas de marketing, identificar patrones y tendencias en el comportamiento del cliente, y mejorar la segmentación y el targeting de las campañas publicitarias.
La herramientas utilizadas en el Big Data Marketing incluyen el análisis de datos, el aprendizaje automático, la inteligencia artificial y la visualización de datos.
Estas tecnologías ayudan a las empresas a procesar grandes cantidades de datos y a generar insights valiosos para mejorar su marketing.
¿CUALES SON LAS 5V DEL BIG DATA?
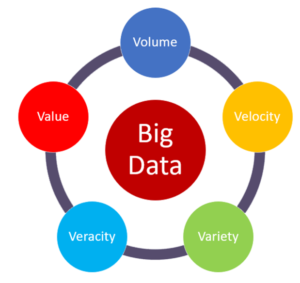
Las 5V del Big Data son cinco características que describen los desafíos asociados con el manejo y el análisis de grandes cantidades de datos.
Estas características son:
Volumen: Se refiere a la cantidad masiva de datos generados por diversas fuentes, como dispositivos móviles, redes sociales, sensores, entre otros.
Velocidad: Se refiere a la rapidez con la que los datos se generan y se recolectan, lo que requiere un procesamiento y análisis en tiempo real.
Variedad: Se refiere a la diversidad de formatos en los que los datos pueden venir, incluyendo datos estructurados, no estructurados y semi estructurados.
Veracidad: Se refiere a la calidad y confiabilidad de los datos, ya que los datos pueden ser incompletos, inexactos o irrelevantes.
Valor: Se refiere a la capacidad de extraer información valiosa y útil de los datos para tomar decisiones informadas.
Entender y manejar estas características es esencial para trabajar con Big Data y obtener insights valiosos.
PYTHON PARA BIG DATA

Python es un lenguaje de programación popular utilizado en el campo del Big Data debido a su facilidad de uso y gran cantidad de librerías y herramientas disponibles para el procesamiento y análisis de datos.
Algunas de las librerías y herramientas de Big Data para Python incluyen:
Pandas: Es una librería de Python que proporciona estructuras de datos y operaciones para manipular y analizar datos de manera eficiente.
NumPy: Es una librería de Python que proporciona funciones matemáticas y estadísticas avanzadas para el análisis de datos.
Scikit-learn: Es una librería de Python que proporciona un conjunto de herramientas de aprendizaje automático para el análisis de datos.
PySpark: Es una interfaz de Python para el motor de procesamiento de datos distribuidos Apache Spark.
Dask: Es una librería de Python que permite trabajar con grandes conjuntos de datos en un solo equipo y distribuir el procesamiento en un cluster.
Matplotlib: Es una librería de Python para la creación de gráficos y visualizaciones de datos.
Estas librerías y herramientas son muy útiles para procesar y analizar grandes cantidades de datos, y son ampliamente utilizadas en el campo del Big Data. Aprender a usarlas es una gran ventaja para los profesionales que quieren trabajar en el campo del Big Data.
BIG QUERY GOOGLE-2023
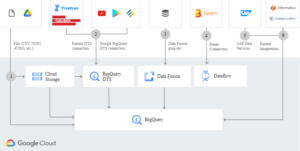
BigQuery es un servicio de análisis de datos en la nube proporcionado por Google Cloud. Es un motor de análisis de datos de alto rendimiento y escalabilidad que permite a los usuarios ejecutar consultas SQL complejas en grandes conjuntos de datos en segundos.
BigQuery también permite a los usuarios cargar, integrar y analizar datos de diferentes fuentes, incluyendo Google Analytics, Google Sheets, Google Drive, entre otros.
Algunas de las características de BigQuery incluyen:
Almacenamiento y procesamiento en la nube: BigQuery permite almacenar y procesar grandes cantidades de datos en la nube, lo que elimina la necesidad de mantener y escalar infraestructura de hardware propia.
Análisis en tiempo real: BigQuery permite ejecutar consultas en tiempo real en grandes conjuntos de datos, lo que permite tomar decisiones informadas de manera rápida.
Integración con otras herramientas: BigQuery se integra con otras herramientas y servicios de Google Cloud, como Google Data Studio, Cloud Dataflow, Cloud Dataproc, entre otros.
Escalabilidad: BigQuery es altamente escalable y permite procesar y analizar grandes volúmenes de datos de manera eficiente.
Seguridad: BigQuery ofrece un alto nivel de seguridad y cumplimiento de normas, lo que permite a las empresas almacenar y procesar datos confidenciales de manera segura.
BigQuery es una excelente opción para las empresas que buscan un servicio de análisis de datos en la nube escalable, de alto rendimiento y seguro.
GOOGLE BIG DATA

Google ofrece una variedad de productos y servicios de Big Data en su plataforma de Google Cloud, que permiten a las empresas almacenar, procesar y analizar grandes cantidades de datos. Algunos de los productos y servicios de Big Data de Google incluyen:
BigQuery: Es un servicio de análisis de datos en la nube que permite a los usuarios ejecutar consultas SQL complejas en grandes conjuntos de datos en segundos.
Cloud Dataflow: Es un servicio de procesamiento de datos en la nube que permite a los usuarios procesar y transformar grandes conjuntos de datos en una variedad de formatos.
Cloud Dataproc: Es un servicio de procesamiento de datos en cluster que permite a los usuarios ejecutar aplicaciones de procesamiento de datos en clusters de máquinas en la nube.
Cloud Storage: Es un servicio de almacenamiento en la nube que permite a los usuarios almacenar grandes cantidades de datos de manera escalable y segura.
Cloud Datalab: Es un servicio de análisis de datos que permite a los usuarios explorar, visualizar y analizar datos mediante el uso de técnicas de aprendizaje automático e inteligencia artificial.
Cloud SQL: Es un servicie de bases de datos relacionales que permite a los usuarios almacenar y gestionar grandes conjuntos de datos en un formato estructurado.
Cloud Pub/Sub: Es un servicio de mensajería en tiempo real que permite a los usuarios procesar grandes volúmenes de datos en tiempo real.
Cloud Data Loss Prevention: Es un servicio de seguridad que permite a los usuarios detectar y prevenir la pérdida de datos confidenciales.
Estos servicios y productos ofrecen a las empresas una variedad de opciones para almacenar, procesar y analizar grandes cantidades de datos, y pueden ser utilizados de manera combinada para crear soluciones de Big Data completas y escalables.
BIG DATA AI

Big Data y la inteligencia artificial (IA) están estrechamente relacionados, ya que la IA se basa en el análisis de grandes cantidades de datos para entrenar y mejorar sus modelos.
La combinación de Big Data e IA permite a las empresas obtener insights valiosos y tomar decisiones informadas de manera automatizada.
Algunas de las formas en las que Big Data e IA se utilizan juntas incluyen:
Análisis predictivo: Utilizando técnicas de aprendizaje automático, las empresas pueden analizar grandes conjuntos de datos históricos para predecir tendencias y comportamientos futuros.
Procesamiento de lenguaje natural (NLP): Utilizando técnicas de NLP, las empresas pueden analizar grandes cantidades de datos de texto para extraer insights valiosos.
Análisis de imágenes y vídeo: Utilizando técnicas de visión artificial, las empresas pueden analizar grandes conjuntos de imágenes y vídeo para extraer información relevante y detectar patrones.
Personalización: Utilizando técnicas de aprendizaje automático, las empresas pueden personalizar la experiencia del usuario y mejorar la segmentación y el targeting de las campañas publicitarias.
Automatización: Utilizando técnicas de aprendizaje automático, las empresas pueden automatizar tareas repetitivas y reducir la carga de trabajo humana.
La combinación de Big Data y IA permite a las empresas obtener una comprensión más profunda de sus clientes y del mercado, lo que se traduce en una ventaja competitiva.
Además, permite a las empresas tomar decisiones informadas y mejorar la eficiencia de sus operaciones de manera automatizada.
MONGODB BIG DATA
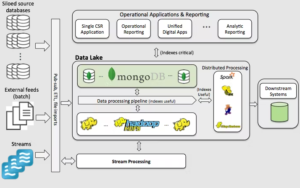
MongoDB es una base de datos NoSQL que es ampliamente utilizada en el campo del Big Data debido a su capacidad para manejar grandes cantidades de datos no estructurados y semi-estructurados.
Algunas de las características de MongoDB que la hacen adecuada para el Big Data incluyen:
Escalabilidad: MongoDB es altamente escalable y permite manejar grandes volúmenes de datos de manera eficiente.
Almacenamiento de documentos: MongoDB utiliza un modelo de almacenamiento de documentos que permite a los usuarios almacenar y recuperar datos no estructurados de manera flexible.
Replicación: MongoDB proporciona un mecanismo de replicación de datos que permite a los usuarios mantener copias de seguridad y mejorar la disponibilidad de los datos.
Sharding: MongoDB proporciona un mecanismo de sharding que permite a los usuarios distribuir los datos en varios servidores para mejorar el rendimiento y la escalabilidad.
Compatibilidad con Cloud: MongoDB se integra con varios proveedores de nubes, incluyendo AWS, Azure, y Google Cloud, lo que permite a las empresas implementarlo en un entorno de nube.
MongoDB es una opción popular para el almacenamiento y el procesamiento de grandes volúmenes de datos no estructurados y semi-estructurados, y es ampliamente utilizado en aplicaciones de Big Data.
BIG DATA CON AMAZON
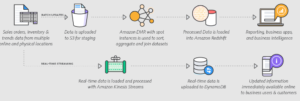
Amazon ofrece una variedad de productos y servicios de Big Data en su plataforma de Amazon Web Services (AWS) que permiten a las empresas almacenar, procesar y analizar grandes cantidades de datos. Algunos de los productos y servicios de Big Data de Amazon incluyen:
Amazon S3: Es un servicio de almacenamiento en la nube que permite a los usuarios almacenar y recuperar grandes cantidades de datos de manera escalable y segura.
Amazon EMR: Es un servicio de procesamiento de datos en cluster que permite a los usuarios ejecutar aplicaciones de procesamiento de datos en clusters de máquinas en la nube.
Amazon Redshift: Es un servicio de almacenamiento de datos en la nube para análisis que permite a los usuarios analizar grandes conjuntos de datos de manera rápida y eficiente.
Amazon QuickSight: Es un servicio de visualización de datos que permite a los usuarios crear visualizaciones y informes interactivos para analizar grandes conjuntos de datos.
Amazon Kinesis: Es un servicio de procesamiento de datos en tiempo real que permite a los usuarios procesar y analizar grandes volúmenes de datos en tiempo real.
Amazon Glue: Es un servicio de extracción, transformación y carga de datos (ETL) que permite a los usuarios preparar y mover grandes conjuntos de datos para su análisis.
Amazon SageMaker: Es un servicio que permite a los usuarios desarrollar, entrenar y desplegar modelos de aprendizaje automático en grandes conjuntos de datos
SCALA Y BIG DATA
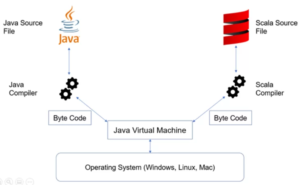
Scala es un lenguaje de programación de alto nivel que se basa en Java Virtual Machine (JVM) y es ampliamente utilizado en el campo del Big Data debido a su capacidad para manejar grandes conjuntos de datos de manera eficiente. Algunas de las razones por las que Scala es adecuado para el Big Data incluyen:
Integración con Java: Scala es compatible con Java y se basa en JVM, lo que permite a los usuarios aprovechar la gran cantidad de librerías y herramientas de Big Data disponibles en Java.
Sintaxis concisa: Scala tiene una sintaxis concisa y expresiva, lo que permite a los desarrolladores escribir código más legible y fácil de mantener.
Funcionalidad: Scala es un lenguaje de programación funcional, lo que permite a los desarrolladores escribir código más conciso y escalable.
Concurrencia: Scala proporciona un modelo de concurrencia incorporado que permite a los desarrolladores escribir código que se ejecuta de manera concurrente y paralela, lo que mejora el rendimiento en el procesamiento de grandes conjuntos de datos.
Integración con Apache Spark: Apache Spark es un motor de procesamiento distribuido de Big Data que está escrito en Scala, lo que permite a los desarrolladores utilizar Scala para programar en Spark y aprovechar sus capacidades de procesamiento de datos en paralelo y escalabilidad.
Comunidad activa: Scala cuenta con una comunidad activa y en constante crecimiento, lo que permite a los desarrolladores obtener ayuda y apoyo en línea, y tener acceso a una gran cantidad de recursos y documentación.
En resumen, Scala es un lenguaje de programación adecuado para el campo del Big Data debido a su capacidad para manejar grandes conjuntos de datos de manera eficiente, su integración con Java y Apache Spark, y su sintaxis concisa y funcionalidad para escribir código escalable y concurrente.
SAS Y BIG DATA
SAS (Statistical Analysis System) es un software de análisis estadístico y minería de datos que se utiliza ampliamente en el campo del Big Data debido a su capacidad para manejar grandes conjuntos de datos y proporcionar herramientas de análisis avanzadas. Algunas de las características de SAS que lo hacen adecuado para el Big Data incluyen:
Análisis estadístico: SAS proporciona una amplia variedad de herramientas de análisis estadístico, incluyendo modelos lineales, análisis de regresión, análisis de series de tiempo, entre otros, que permiten a los usuarios analizar grandes conjuntos de datos de manera precisa.
Minería de datos: SAS proporciona herramientas de minería de datos, incluyendo análisis de clusters, análisis de reglas de asociación, y análisis de redes, que permiten a los usuarios descubrir patrones y relaciones en grandes conjuntos de datos.
Integración con fuentes de datos: SAS se integra con una variedad de fuentes de datos, incluyendo bases de datos relacionales, hojas de cálculo, y archivos de texto, lo que permite a los usuarios importar y analizar grandes conjuntos de datos.
Visualización de datos: SAS proporciona herramientas de visualización de datos, incluyendo gráficos y tablas dinámicas, que permiten a los usuarios presentar los resultados del análisis de manera clara y fácil de entender.
Escalabilidad: SAS es escalable y puede manejar grandes volúmenes de datos de manera eficiente, con una capacidad de procesamiento de datos de hasta terabytes.
BIG QUERY GOOGLE ANALYTICS
Google BigQuery es un almacén de datos nativo de la nube totalmente administrado que permite realizar consultas SQL superrápidas mediante el poder de procesamiento de la infraestructura de Google.
Le permite analizar conjuntos de datos grandes y complejos utilizando un lenguaje similar a SQL.
También se integra con otros servicios de Google Cloud y permite a los usuarios ejecutar análisis interactivos de grandes conjuntos de datos con la capacidad de unir datos de una variedad de fuentes.
Google Analytics, por otro lado, es un servicio de análisis web ofrecido por Google que rastrea e informa el tráfico del sitio web.
Le permite realizar un seguimiento del comportamiento de los visitantes de su sitio web, incluido el número de visitantes, las páginas que visitan y cuánto tiempo permanecen.
También proporciona información sobre cómo los visitantes interactúan con su sitio web, como qué palabras clave usaron para encontrar su sitio, de dónde fueron referidos y qué tipo de dispositivo estaban usando.
Google BigQuery y Google Analytics se pueden integrar juntos, lo que le permite combinar datos de estas dos fuentes y realizar análisis avanzados. Esta integración le permite analizar grandes cantidades de datos de múltiples fuentes, incluidos los datos de tráfico del sitio web, para obtener información y tomar decisiones basadas en datos.